配列とリンクリストの違い

コンテンツ
間の主な違い アレイ そして リンクリスト それらの構造に関して。配列は インデックスベース 各要素がインデックスに関連付けられているデータ構造。一方、リンクリストは、 参照 各ノードは、データと前および次の要素への参照で構成されます。
基本的に、配列は、共通の見出しまたは変数名でシーケンシャルなメモリ位置に保存された同様のデータオブジェクトのセットです。
リンクリストは、各要素が次の要素にリンクされている要素のシーケンスを含むデータ構造です。リンクリストの要素には2つのフィールドがあります。 1つはデータフィールドで、もう1つはリンクフィールドです。データフィールドには、保存および処理される実際の値が含まれます。さらに、リンクフィールドには、リンクリスト内の次のデータ項目のアドレスが保持されます。特定のノードへのアクセスに使用されるアドレスは、ポインターと呼ばれます。
配列とリンクリストのもう1つの重要な違いは、配列のサイズが固定されており、事前に宣言する必要があることです。
- 比較表
- 定義
- 主な違い
- 結論
比較表
| 比較の根拠 | アレイ | リンクリスト |
|---|---|---|
| ベーシック | これは、一定数のデータ項目の一貫したセットです。 | これは、可変数のデータ項目で構成される順序付きセットです。 |
| サイズ | 宣言中に指定されます。 | 指定する必要はありません。実行中に拡大および縮小します。 |
| ストレージ割り当て | エレメントの場所はコンパイル時に割り当てられます。 | エレメントの位置は実行時に割り当てられます。 |
| 要素の順序 | 連続して保存 | ランダムに保存 |
| 要素へのアクセス | 直接またはランダムにアクセスします。つまり、配列のインデックスまたは添え字を指定します。 | 順次アクセス、つまり、リスト内の最初のノードからポインターで始まるトラバース。 |
| 要素の挿入と削除 | シフトが必要なため、比較的低速です。 | より簡単、高速、効率的。 |
| 検索中 | バイナリ検索と線形検索 | 線形探索 |
| 必要なメモリ | もっと少なく | もっと |
| メモリ使用率 | 無効 | 効率的 |
配列の定義
配列は、一定数の同種の要素またはデータ項目のセットとして定義されます。つまり、配列には、すべての整数、すべての浮動小数点数、またはすべての文字のいずれかのタイプのデータのみを含めることができます。配列の宣言は次のとおりです。
int a;
intは、データ型または型要素の配列ストアを指定します。 「a」は配列の名前で、角括弧内に指定された数字は配列が保存できる要素の数です。これは配列のサイズまたは長さとも呼ばれます。
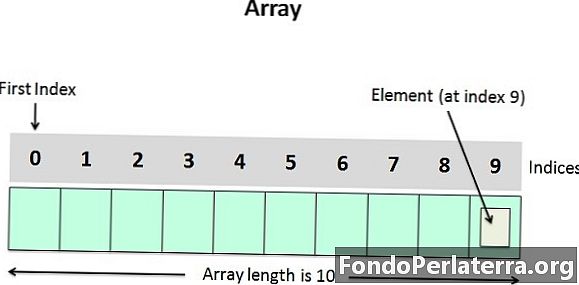
配列について覚えておくべきいくつかの概念を見てみましょう。
- 配列の個々の要素にアクセスするには、配列の名前を記述し、その後に角かっこ内のインデックスまたは添え字(配列内の要素の位置を決定する)を記述します。たとえば、配列の5番目の要素を取得するには、ステートメントaを記述する必要があります。
- いずれにせよ、配列の要素は連続したメモリ位置に保存されます。
- 配列の最初の要素のインデックスは0です。これは、最初と最後の要素がそれぞれaおよびaとして指定されることを意味します。
- 配列に格納できる要素の数、つまり配列のサイズまたはその長さは、次の式で与えられます:
(上限-下限)+ 1
上記の配列の場合、(9-0)+ 1 = 10になります。 0は配列の下限、9は配列の上限です。 - ループを介して配列を読み書きできます。 1次元配列を読み取る場合、配列の読み取り(書き込み)に1つのループが必要です。たとえば、次のとおりです。
a。配列を読み取るため
for(i = 0; i <= 9; i ++)
{scanf(“%d”、&a); }
b。配列を書き込むため
for(i = 0; i <= 9; i ++)
{f(“%d”、a); } - 2次元配列の場合、2つのループが必要になり、同様にn次元配列にはnループが必要になります。
配列で実行される操作は次のとおりです。
- 配列の作成
- 配列の横断
- 新しい要素の挿入
- 必要な要素の削除。
- 要素の変更。
- 配列のマージ
例
次のプログラムは、配列の読み取りと書き込みを示しています。
#含める
#含める
void main()
{
int a、i;
f( "Enter the array");
for(i = 0; i <= 9; i ++)
{
scanf( "%d"、&a);
}
f( "Enter the array");
for(i = 0; i <= 9; i ++)
{
f( "%d n"、a);
}
getch();
}
リンクリストの定義
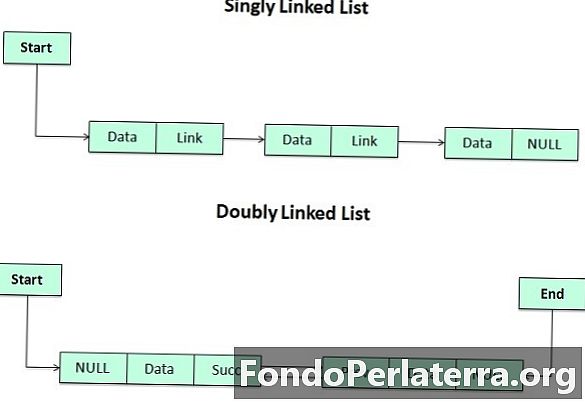
リンクリストは、互いにリンクされたいくつかのデータ要素の特定のリストです。このすべての要素は、論理的な順序を表す次の要素を指します。各要素はノードと呼ばれ、2つの部分があります。
情報を格納するINFOパートと次の要素を指すPOINTER。アドレスの保存について知っているように、Cと呼ばれるポインターと呼ばれる一意のデータ構造があります。したがって、リストの2番目のフィールドはポインター型でなければなりません。
リンクリストのタイプは、単一リンクリスト、二重リンクリスト、円形リンクリスト、円形二重リンクリストです。
リンクリストで実行される操作は次のとおりです。
- 作成
- 横断
- 挿入
- 削除
- 検索中
- 連結
- 表示
例
次のスニペットは、リンクリストの作成を示しています。
構造体ノード
{
int num;
stuct node * next;
}
start = NULL;
void create()
{
typedef struct node NODE;
NODE * p、* q;
文字の選択;
最初= NULL;
行う
{
p =(ノード*)malloc(sizeof(ノード));
f(「データ項目を入力してください n」);
scanf( "%d"、&p-> num);
if(p == NULL)
{
q =開始;
while(q-> next!= NULL)
{q = q->次
}
p-> next = q-> next;
q-> = p;
}
他に
{
p-> next = start;
start = p;
}
f(「続行しますか(yまたはnを入力しますか?) n」);
scanf( "%c"、&choice);
}
while((choice == y)||(choice == Y));
}
- 配列は、同様のタイプのデータ要素のコレクションを含むデータ構造ですが、リンクリストは、ノードと呼ばれる順序付けられていないリンク要素のコレクションを含む非プリミティブデータ構造と見なされます。
- 配列では、要素はインデックスに属します。つまり、4番目の要素にアクセスする場合は、インデックスまたは角括弧内の位置を使用して変数名を記述する必要があります。
ただし、リンクリストでは、先頭から始めて、4番目の要素に到達するまで作業を進めなければなりません。 - 要素リストへのアクセスは高速ですが、リンクリストは線形時間を要するため、かなり遅くなります。
- 配列への挿入や削除などの操作には多くの時間がかかります。一方、リンクリストでのこれらの操作のパフォーマンスは高速です。
- 配列のサイズは固定です。対照的に、リンクリストは動的で柔軟であり、サイズを拡大および縮小できます。
- 配列では、メモリはコンパイル時に割り当てられ、リンクリストでは実行または実行時に割り当てられます。
- 要素は配列に連続して格納されますが、リンクリストにはランダムに格納されます。
- 配列のインデックス内に実際のデータが保存されるため、メモリの要件は少なくなります。反対に、追加の次および前の参照要素を保存するため、リンクリストにはより多くのメモリが必要です。
- さらに、アレイのメモリ使用率は非効率的です。逆に、メモリ使用率はアレイで効率的です。
結論
配列リストとリンクリストは、構造、アクセス方法と操作方法、メモリ要件と使用率が異なるデータ構造のタイプです。また、その実装に対して特定の利点と欠点があります。したがって、必要に応じていずれかを使用できます。





