クラウドコンピューティングとビッグデータの違い

コンテンツ
クラウドコンピューティングは統合された方法で機能し、ビッグデータはクラウドコンピューティングの下にあります。クラウドコンピューティングとビッグデータの重要な違いは、クラウドコンピューティングを使用して、コンピューティングリソースとストレージリソースを拡張することにより、膨大なストレージ容量(ビッグデータ)を処理することです。一方、ビッグデータは、構造化されていない冗長でノイズの多い膨大な量のデータと、そこから有用な知識を抽出する必要がある情報に他なりません。上記の機能を実行するために、クラウドコンピューティングテクノロジーは、膨大な量のデータに対処するためのさまざまな柔軟な手法を提供します。
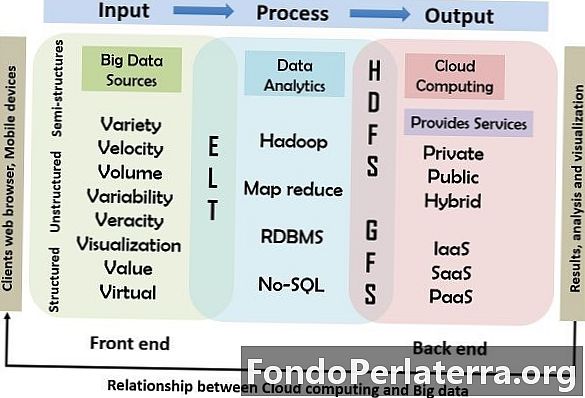
これには、以下で説明する入力、処理、および出力モデルが含まれます。この図は、クラウドコンピューティングとビッグデータの関係を詳細に示しています。
-
- 比較表
- 定義
- 主な違い
- 結論
比較表
| 比較の根拠 | クラウドコンピューティング | ビッグデータ |
|---|---|---|
| ベーシック | オンデマンドサービスは、統合されたコンピューターリソースとシステムを使用して提供されます。 | 構造化された、構造化されていない、複雑なデータの広範なセットが、従来の処理技術を使用することを禁止しています。 |
| 目的 | データをリモートサーバーに保存および処理し、任意の場所からアクセスできるようにします。 | 隠された貴重な知識を抽出するための大量のデータと情報の編成。 |
| ワーキング | 分散コンピューティングを使用して、データを分析し、より有用なデータを生成します。 | インターネットは、クラウドベースのサービスを提供するために使用されます。 |
| 長所 | 低いメンテナンス費用、中央集中型プラットフォーム、バックアップとリカバリのプロビジョニング。 | 費用対効果の高い並列処理、スケーラブル、堅牢。 |
| 課題 | 可用性、変換、セキュリティ、課金モデル。 | データの多様性、データストレージ、データ統合、データ処理、およびリソース管理。 |
クラウドコンピューティングの定義
クラウドコンピューティング 高速インターネットを使用して、オンデマンドでどこからでも、いつでも、任意の量のデータを保存および取得するためのサービスの統合プラットフォームを提供します。クラウドは、データを保存、管理、処理するためにインターネット上に分散された幅広い地上サーバーのセットです。クラウドコンピューティングは、開発者がWebスケールコンピューティングを簡単に実装できるように開発されています。インターネットはクラウドコンピューティングの基盤であるため、インターネットの進化によりクラウドコンピューティングモデルが生まれました。クラウドコンピューティングを効率的に機能させるには、高速インターネット接続が必要です。容量と機能を動的に追加し、従量課金戦略に従って使用できる柔軟な環境を提供します。
クラウドコンピューティングには、リソースプーリング、オンデマンドセルフサービス、広範なネットワークアクセス、測定されたサービス、迅速な弾力性など、いくつかの重要な特性があります。クラウドには、パブリック、プライベート、ハイブリッド、コミュニティの4つのタイプがあります。
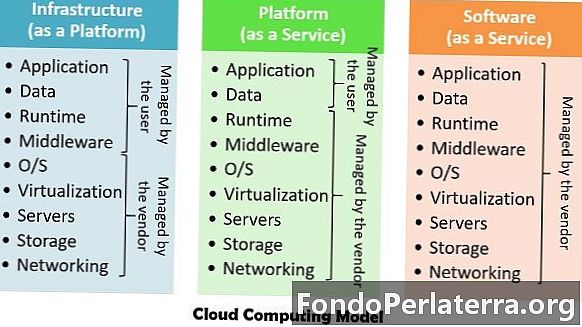
基本的に3つのクラウドコンピューティングモデルがあります。Platformas a Service(Paas)、Infrastructure as a Service(Iaas)、Software as a Service(Saas)で、ハードウェアとソフトウェアサービスを使用します。
- サービスとしてのインフラストラクチャ –このサービスは、ストレージ処理能力と仮想マシンを含むインフラストラクチャの提供に使用されます。サービスレベル契約(SLA)に基づいてリソースの仮想化を実装します。
- サービスとしてのプラットフォーム –プログラミングおよびランタイム環境を提供するIaaSレイヤーの上にあり、ユーザーがクラウドアプリケーションを展開できるようにします。
- サービスとしてのソフトウェア –クラウドプロバイダーで直接実行されるアプリケーションをクライアントに配信します。
ビッグデータの定義
データは次のようになります ビッグデータ ITシステムの能力を超えるボリューム、多様性、速度の増加により、データの保存、分析、処理が困難になります。一部の組織は、このタイプの大量の構造化データを処理するための機器と専門知識を開発しましたが、指数関数的に増加するボリュームとデータの迅速な流れにより、 私の それとすぐに実用的なインテリジェンスを生成します。この膨大なデータを通常のデバイスに保存したり、分散環境に分散したりすることはできません。ビッグデータコンピューティングは、 データサイエンス 大規模インフラストラクチャでの科学的発見とビジネス分析のための多次元情報マイニングに集中しています。
ビッグデータの基本的な次元は、ボリューム、速度、多様性、および正確性であり、これらも上記で説明したように、後でさらに2つの次元が展開され、変動性と価値があります。
- ボリューム –データの処理と保存がすでに問題となっている増加するデータのサイズを示します。
- 速度 –データがキャプチャされるインスタンスとデータのフロー速度です。
- バラエティ –データは常に単一の形式で表示されるわけではなく、たとえば、音声、画像、ビデオなど、さまざまな形式のデータがあります。
- 正確さ –データの信頼性と呼ばれます。
- 変動性 –ビッグデータで生じる信頼性、複雑さ、および矛盾を説明します。
- 値 –コンテンツの元の形式はあまり有用で生産的ではない可能性があるため、データが分析され、価値の高いデータが発見されます。
- クラウドコンピューティングは、インターネット上に分散されたコンピューティングリソースを使用して、オンデマンドで提供されるコンピューティングサービスです。一方、ビッグデータは、従来のアルゴリズムや手法では処理できない構造化、非構造化、半構造化データを含む、大量のコンピューターデータのセットです。
- クラウドコンピューティングは、ユーザーにSaas、Paas、Iaasなどのサービスをオンデマンドで利用するためのプラットフォームを提供し、使用に応じてサービスの料金も請求します。対照的に、ビッグデータの主な目的は、膨大なデータのコレクションから隠された知識とパターンを抽出することです。
- 高速インターネット接続は、クラウドコンピューティングに不可欠な要件です。反対に、ビッグデータは分散コンピューティングを使用してデータを分析およびマイニングします。
クラウドコンピューティングとビッグデータの関係
以下に示す図は、ビッグデータとクラウドコンピューティングの関係と動作を示しています。このモデルでは、マウス、キーボード、携帯電話、その他のスマートデバイスなどの入力デバイスを使用してビッグデータがシステムに挿入される参照として、プライマリ入力、処理、および出力コンピューティングモデルが使用されます。処理の第2段階には、サービスを提供するためにクラウドで使用されるツールと技術が含まれます。最後に、処理の結果がユーザーに配信されます。
結論
クラウドコンピューティングテクノロジーは、使いやすさ、リソースへのアクセス、需要と供給のリソース使用の低コストにより、ビッグデータに適した準拠フレームワークを提供し、ビッグデータの処理に使用される堅牢な機器の使用を最小限に抑えます。クラウドとビッグデータの両方は、投資コストを削減しながら企業の価値を高めることに重点を置いています。



の違い")

